通过3CX CFD使用谷歌云端语音识别服务

介绍:
谷歌云作为云服务平台服务商,提供了文本转语音Text To Speech(TTS)和语音转文本Speech To Text(STT)。3CX支持这两种服务,第一种是作为文本到语音的替代引擎,第二种是通过语音输入组件( Voice Input component)提供语音识别。要使用此功能,您需要3CX电话系统v16 update 6或更高版本。
本指南介绍了如何创建Google 云账户,如何启用文本转语音/语音转文本服务,以及如何在CFD应用程序中使用这些服务。
提示:该示例应用程序的项目可通过CFD 示例 GitHub页面获得,并与3CX呼叫流设计器一起安装在您的Windows用户文档文件夹中,即 “C:\Users\YourUsername\Documents3CX Call Flow Designer Demos”。
使用Google Cloud进行文字转语音
很多时候,需要再现无法预先录制的音频,例如从数据库获得的名称,地点或某些任务描述。在这些情况下,可以使用文本语音转换(TTS),让我们为CFD应用程序动态创建WAV文件,以将其回放给主叫方。
3CX呼叫流程设计器包括“文本到语音音频(Text to Speech Audio) ”提示,当使用“提示音播放”组件(Prompt Playback component),“菜单”组件(Menu component),“用户输入”组件(User Input component)等配置提示时使用。
CFD应用程序在将消息播放给呼叫者之前,实时将文本转换为语音。它调用Web服务以获取音频流,并将其保存到本地为WAV文件。最后,当呼叫结束时,将自动删除WAV文件以保持系统干净。
要使用TTS,您可以使用Google Cloud或Amazon Web Services提供的引擎。本指南说明了如何使用Google Cloud设置CFD应用。要将TTS与Amazon Web Services结合使用,请参阅本指南。
在选择Google Cloud引擎之前,请检查语言覆盖范围和可用的声音。
使用Google Cloud语音转文字
您可以使用语音输入组件(Voice Input component)启用呼叫者的语音识别,并将结果转换为文本。 例如,您可以要求您的客户口头指定:
- 一个字母数字ID,因此您可以使用它进行数据库查找。
- 公司内自动将呼叫者连接到适当目的地的人员或部门的名称。
该组件将呼叫者音频实时发送到Google Cloud,并实时接收回识别信息,从而验证流程中的输入。
在开始使用语音识别的CFD项目之前,请检查支持的语言。
步骤1:建立Google Cloud帐户
在开始进行CFD项目之前,您需要一个Google Cloud帐户。 要创建它,请转到Google Cloud 控制台,然后按照说明激活您的帐户。
步骤2:建立Google Cloud项目
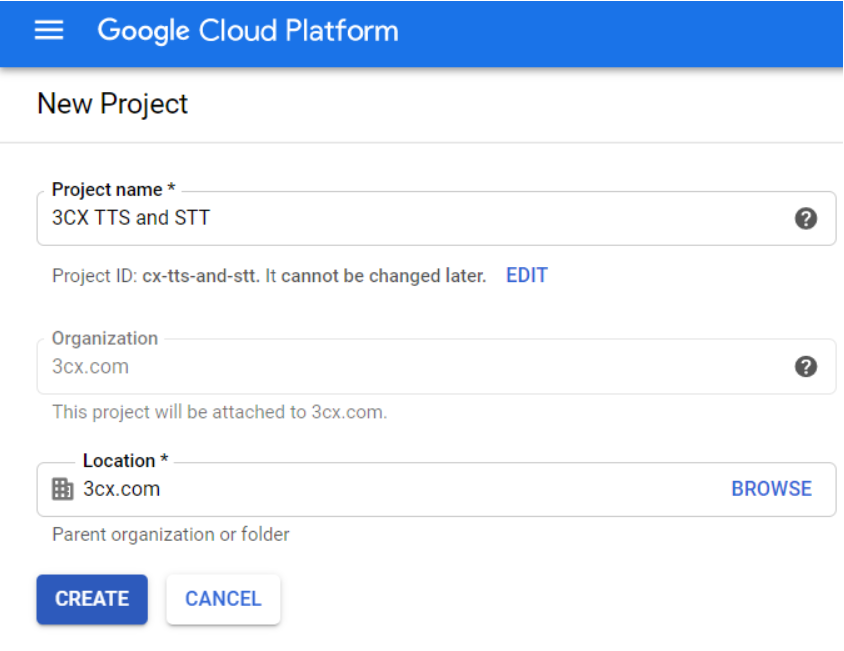
启用Google Cloud帐户后,请转到Google Cloud 控制台,然后:
- 用适当的名称创建一个新项目,例如 “ 3CX TTS and STT”,然后单击“创建(CREATE)”。在Google Cloud Console中启用API服务。
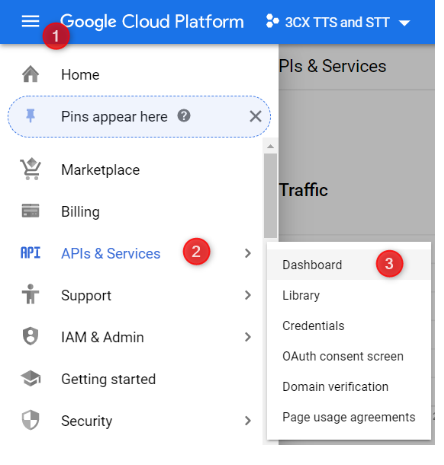
- 通过转到“菜单(Menu)”>“ API和服务(APIs & Services)”>“仪表板(Dashboard)”,然后单击“ +启用API和服务(+ ENABLE APIS & SERVICES)”来启用所需的API。 选择并启用以下服务:
A. Cloud Speech-to-Text API.
B. Cloud Text-to-Speech API.

- 要创建服务帐户,以便CFD应用可以通过Google Cloud进行身份验证并使用此项目,请转到“菜单(Menu)”>“ IAM和管理员(IAM & Admin)”>“服务帐户(Service Accounts)”,然后单击“ +创建服务帐户(+ CREATE SERVICE ACCOUN)”

- 用适当的值填写服务帐户详细信息,然后单击“创建(CREATE)”。
- 将“角色(Role)”设置为“项目所有者”,然后单击“继续(CONTINUE)”。
- 在“授予用户访问此服务帐户的权限(Grant users access to this service account)”部分中,将字段保留为空,然后单击“完成(DONE)”。
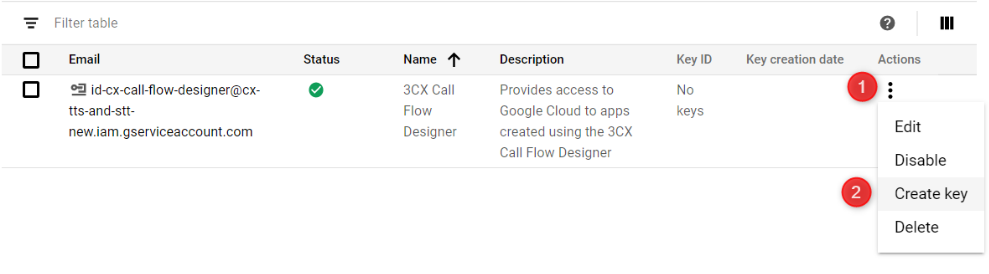
- 在包含服务账户详情的新行中,点击右侧的3个点,选择 “创建密钥(Create key)”。
- 选择JSON,然后点击 “创建(CREATE )”将JSON文件下载到您的计算机。将此文件存储在安全位置,以便访问您的云资源。您需要这个文件来配置CFD应用程序中的 “在线服务(Online Services)”。
步骤3:创建CFD项目
准备好您的Google Cloud帐户后,您可以继续创建我们的Call Flow Designer项目:
- 打开CFD并转到“文件(File)”>“新建(New)”>“项目(Project)”,选择要保存的文件夹,然后输入项目的名称,例如 “ SpeechToTextDemo”。
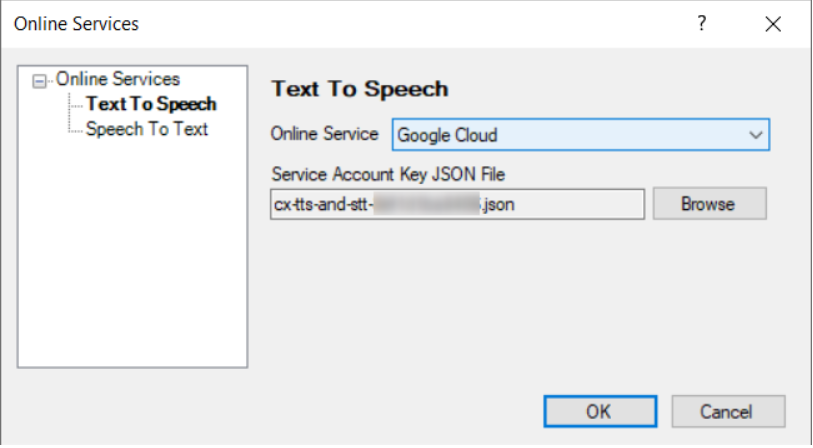
- 转到“工具(Tools)”>“在线服务(Tools)”菜单,然后:
在“文字转语音(Text To Speech)”下,选择:
A.“Online Service”: Google Cloud
B. “服务帐户密钥JSON文件(Service Account Key JSON File)”:选择在上一步中下载的JSON文件。
在“语音转文字(Speech To Text)”下,选择:
- “Online Service”: Google Cloud
- “服务帐户密钥JSON文件(Service Account Key JSON File)”:已经选择了JSON文件,因为它与TTS和STT相同。
这些设置用于项目中的每个“文本到语音”音频提示和“语音输入”组件。
步骤4:添加“语音输入”组件( “Voice Input” Component)
“语音输入 “组件可以让你配置提示,要求呼叫者输入,所以在这个演示中,在同一个组件中同时使用了 “文本到语音 “和 “语音到文本”。在进入 “语音输入 “之前,首先添加 “Prompt Playback “组件以提供欢迎信息。
要添加 “Prompt Playback “组件:
- 从工具箱中拖动一个 “Prompt Playback “组件,并将其放到 “Main “调用流的设计视图中。然后选中添加的组件,进入 “Properties “将其重命名为 “Welcome”。
- 从 “Properties “中打开 “Prompt Collection Editor”,点击 “Prompts “属性右侧的按钮。
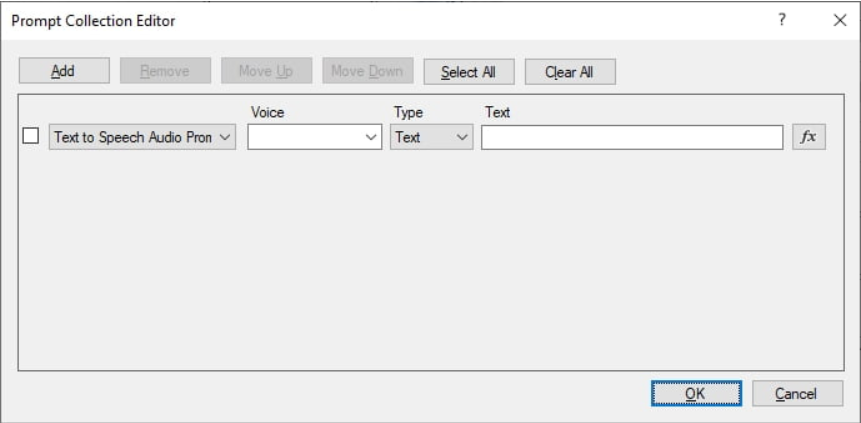
- 单击“Add”将新提示添加到集合中,然后将类型更改为“Text to Speech Audio Prompt”。
- 选择要使用的声音。语音的下拉列表按语言排序,因此您可以轻松找到所需的可用语言选项。
注意:此处列出了可用于Google Cloud的声音。 如果Google Cloud发布了尚未包含在此下拉列表中的新语音,则只需在“语音名称”列中输入值即可使用它。 如果要预设定特定的声音,可以从“Tools”>“Options”>“Component Templates”>“Text To Speec”进行设置。 对于此演示,使用“en-US-Standard-B (English – US, Male)”语音配置文件。
- 选择文本类型:
“Text”–“Text “属性的值被TTS引擎视为纯文本,将其转换为语音一样。”Text “在本例中被设置为代表典型用法。
“SSML”(语音合成标记语言)–根据SSML规范,”Text “属性的值被视为XML。使用SSML,您可以控制语音的各个方面,如发音、音量、音调和语速。更多信息,请参见Google关于使用SSML的指南。
- 输入文本的表达式。 根据上一步中选择的类型,表达式必须返回纯文本以转换为语音,或者根据SSML规范转换为XML。 对于此演示,可以使用此静态文本:
“Welcome to this speech recognition demo application.”
要添加“语音输入”组件:
- 从工具箱中拖动一个 “Voice Input “组件,并将其放入 “Main “呼叫流的设计视图中。然后选择添加的组件,进入 “Properties”,重命名为 “AskForDepartment”。
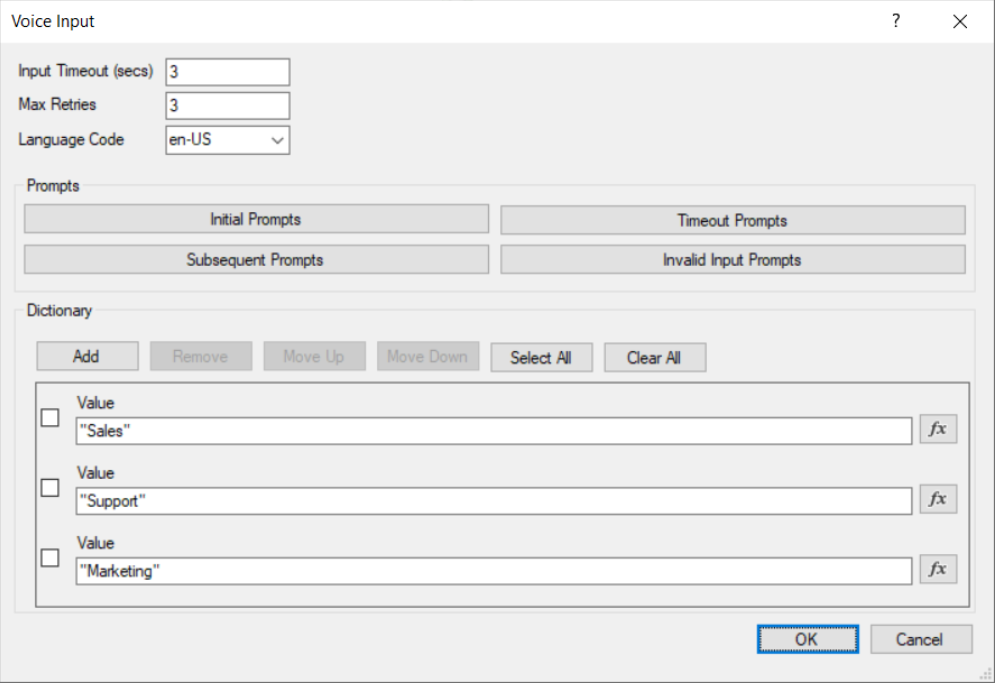
- 双击添加的组件以启动配置对话框并设置:
a“Input Timeout”:3秒。 这意味着该组件将尝试识别音频,直到呼叫者在3秒钟内保持沉默,或者它识别出某些东西为止。
b “Max Retries”:3.这意味着当用户保持沉默或输入无效时,该组件最多重复提示输入3次。
c “Language Code”:选择“ en-US”。
d 对于提示,请使用“Text to Speech Audio Prompts”,并为每个提示配置以下文本:
“Initial Prompts”:“请说出您要连接的部门名称,例如销售,支持或市场部门。”
“Subsequent Prompts”:“让我们再试一次。说出您要连接的部门的名称,例如销售,支持或营销部门。”
“Timeout Prompts”:“对不起,我听不到您的声音。”
“Invalid Input Prompts”:“很抱歉,您需要说出有效的选项之一,例如“销售”,“支持”或“营销”。
e 对于“Dictionary”,您可以定义三(3)个有效选项:“销售”,“支持”和“营销”。 这意味着“语音输入”组件将尝试在识别的文本中识别这些术语之一。 完成后,语音识别结束,组件继续前进。
- 当 “语音输入 “组件从字典中识别出一个条目时,在 “有效输入 “分支中继续执行。在这种情况下,你需要使用 “创建条件 “组件检查识别到的内容,然后将调用转移到相应的目的地。将工具箱中的这个组件添加到 “Valid Input “分支中,将其命名为 “CheckRecognition”,并将该组件配置为三(3)个分支。”销售(Sales)”、”支持 (Support)”和 “营销(Marketing)”。
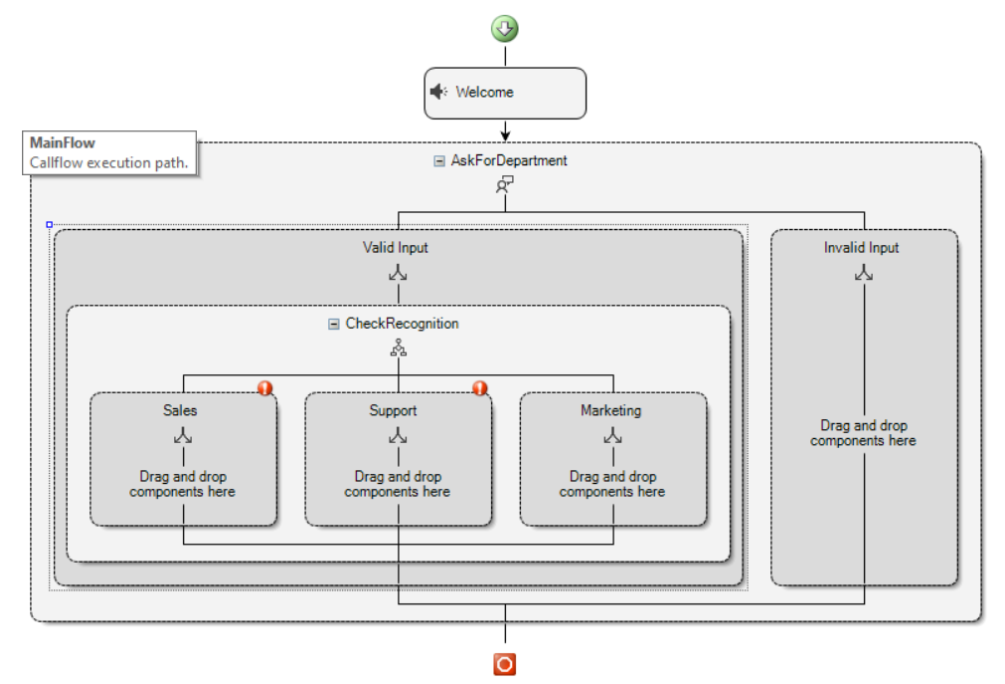
- 对于Sales分支,在Condition属性中使用以下表达式:
EQUAL(AskForDepartment.DictionaryMatch,”Sales”)
- 对于Support分支,请在Condition属性中使用以下表达式:
EQUAL(AskForDepartment.DictionaryMatch,”Support”)
- 对于Marketing分支,请将Condition保留为空,以便在跳过前两个分支时执行该分支。
- 在每个分支中,添加一个“Transfer”组件,该组件配置为将呼叫转接到适当的目的地。
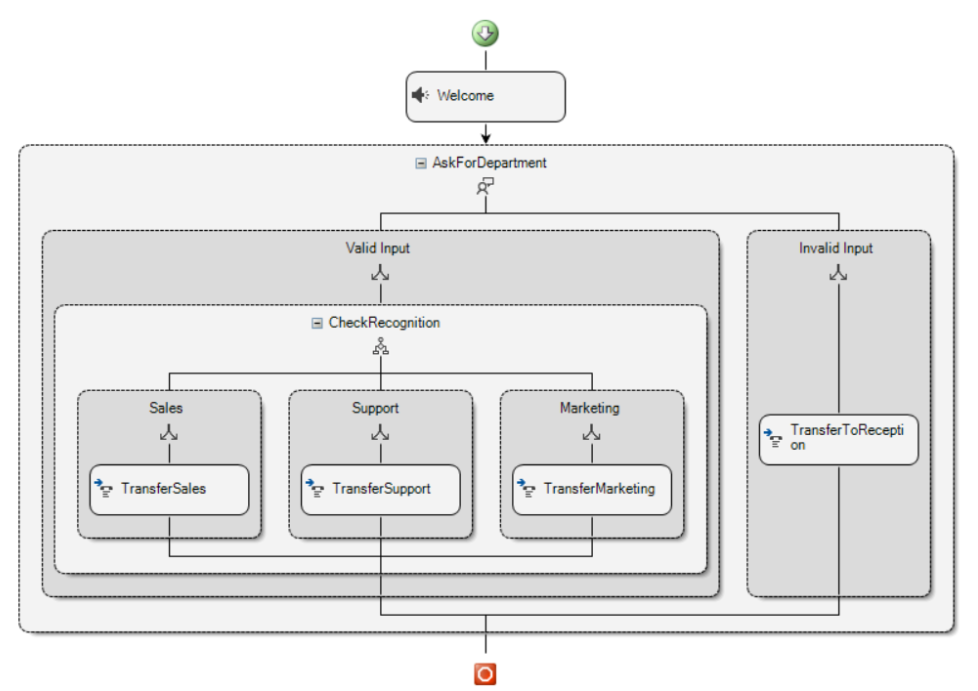
- 最后,将另一个“Transfer”组件添加到“Invalid Input”分支,以便可以将呼叫转接到接待员。
步骤5:构建并部署到3CX电话系统
该项目已准备就绪,可以通过以下步骤构建并上传到我们的3CX电话系统服务器:
- 选择“Build”>“Build All”,CFD生成文件“ SpeechToTextDemo.zip”。
- 转到“ 3CX管理控制台”>“高级”>“呼叫流程应用程序”>“添加/更新”,然后上载CFD在上一步中创建的文件。
- 呼叫流程应用已准备就绪,可以使用。 拨打电话以测试此应用。请注意,第一次调用此应用程序时,第一次文本到语音的转换和第一次语音识别可能会有短暂的延迟。这与身份验证过程有关,并且仅在您首次调用该应用程序时发生。